

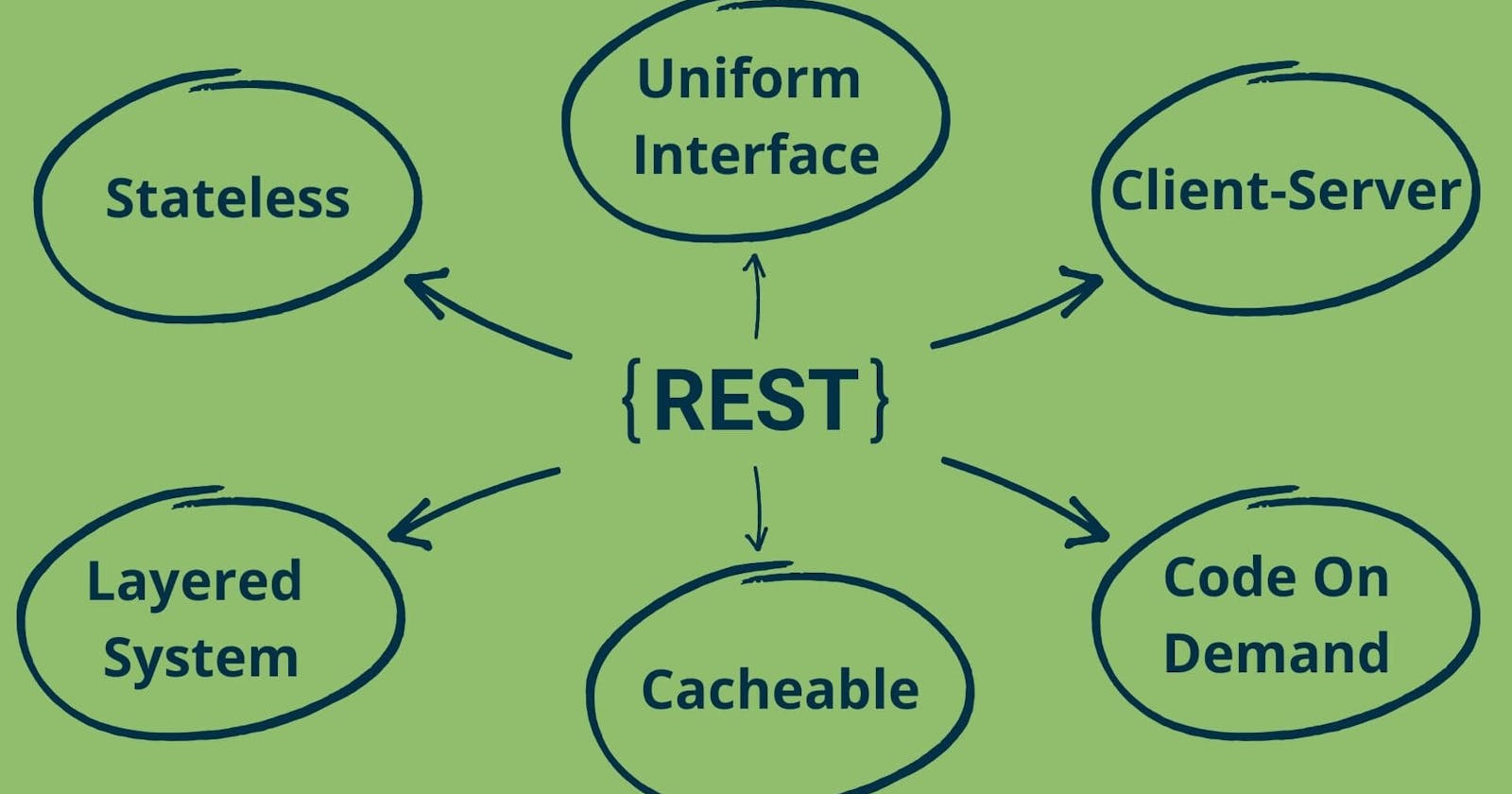
REST Architectural Constraints: The 6 guiding principles behind a truly RESTful API
Uniform Interface, Stateless, Client-Server, Cacheable, Layered System and Code-On-Demand are the six foundational principles behind a RESTful API.


In the previous article we learned the basics of REST architecture and discussed what are APIs, Web APIs, Web Services and REST APIs.
In this article, we'll learn the 6 REST architectural constraints. An API that properly implements these constraints is termed a REST API or a RESTful API.
Each of these constraints contributes distinct benefits to the overall architecture like server scalability and performance improvements along with establishing a standard for API implementations.
Many API designers make the mistake of designing "REST" APIs without proper knowledge of these constraints. While there is nothing wrong with custom API implementations, they cannot be termed as truly RESTful and will not be able to take full advantage of the incredible merits of an exhaustively researched framework for API design.
Having established the importance of learning and implementing these constraints, let's get started with exploring these one by one.
This is the second blog post in a 3-part article series.
The first and the second articles throw light on the core REST architectural concepts.
For a more practical approach to learning how to design a RESTful API, please refer to the third article which involves a hands-on, step-by-step tutorial that will walk you through building a truly RESTful API using NodeJS and ExpressJS.
Client-Server
This constraint essentially necessitates "separation of concerns" by separating the UI logic from data-storage and business logic.
The server-side of the program is responsible for managing data and applying business logic, exposing API services and listening and responding to requests from clients.
The client is responsible for invoking API requests, managing the user interface and user experience.
The client does not need to know any backend implementation details like which database is being used, etc. All it needs to know is how to invoke the API services exposed by the server.
Similarly the server doesn't need to know any frontend implementation details like whether the client is using ReactJS or something else for rendering the User Interface.
This allows both the server and the client to evolve independently as long as the API interface between them remains unchanged.
For example, consider a web app where the front-end and the back-end are tightly coupled meaning the pages are server-rendered and the HTML code is mixed with server-side business logic.
As the customer base increases, the app developers feel the need for an iOS app, an Android app and a desktop app. Duplicating the backend code and business logic for each of these seems too redundant.
So the developers implement a REST API on the server and separate the front-end logic for each of these client apps. These client apps implement their UIs differently but source their data from the same API services. This eliminates coupling and avoids duplicating business and data-storage logic.
Later down the line, the devs can even decide to switch databases from say SQL server to MongoDB or maybe switch the server-side programming language from PHP to NodeJS but as long as they don't alter the API interface meaning the URIs, the API inputs and response, the client apps will not be affected.
The developers can even expose a subset of these APIs to other third-party apps for integration and they can consume these APIs in the same way as the in-house client apps.
Stateless
Ever seen the movie 50 First Dates where Drew Barrymore forgets everything from the previous day and Adam Sandler has to try to win her over again every day?
Well this constraint is kind of like that with the client being Adam Sandler and server being Drew Barrymore.
It specifies that the API server must not store any information about the client's session state for servicing future API requests and must treat every client request as new. Hence the term stateless.
In case the application needs to manage user sessions, it must manage them entirely on the client-side and every API request should carry some form of authentication credential to authorize the request.
For example, Github's REST API requires the client to send an "Authorization Token" with each request for authentication.
curl -H "Authorization: Bearer OAUTH-TOKEN" https://api.github.com/user
This constraint simplifies the API implementation and also improves scalability as not having to store every user's session information between multiple requests quickly frees up resources on the server.
Cacheable
This constraint implies that whenever possible, the API implementation should instruct the client to cache the API response. For future API requests, the client can use the cached data instead of invoking the API service again.
REST API services should implicitly or explicitly declare which resources are cacheable or non-cacheable. These caching instructions are provided by the server in the form of HTTP headers in the response and helps the client determine when the response data in the cache should be considered as stale and should be replaced with fresh response data from the API service.
These caching preferences are controlled by sending HTTP headers in the response. The most prominently used caching headers include Cache-Control, Age, ETag, Last-Modified and Expires.
Consider the Github API as an example.
GET https://api.github.com/users/saurabh-misra/
If you visit the above URL in your browser, it will send a GET request to Github's API and will render a JSON response on the screen. If you analyze the response headers in your browser's dev tools, you'll see something like this:
HTTP/2 200 OK
server: GitHub.com
date: Sat, 11 Mar 2023 14:58:18 GMT
content-type: application/json; charset=utf-8
cache-control: public, max-age=60, s-maxage=60
vary: Accept, Accept-Encoding, Accept, X-Requested-With
etag: W/"6feaef1f6675360ef8c4d59e6dc55c4b883cd00032cafcb412ee156ab11b1f1d"
last-modified: Sun, 19 Feb 2023 18:10:02 GMT
...
...
Github here is trying to tell any clients invoking this API service that the response can be stored in a cache and can be considered fresh for 60 seconds using the Cache-Control header. After 60 seconds, clients should confirm whether the data is still fresh or has become stale from the API server by using the values from the ETag and Last-Modified headers.
We'll not just discuss Caching in more detail but also learn how to implement it with the help of a tutorial in the next article in this series.
When properly implemented, caching can partially reduce or sometimes completely eliminate the need for client-server interactions thereby improving scalability on the server i.e. the server will need to service fewer API requests which will leave server resources free for other requests.
On the client side, it can improve user-perceived performance as HTTP calls to the API will be replaced by cache fetch requests which are faster thereby reducing latency.
The trade-off however is that caching affects reliability of the data in the cache because it can potentially differ from the fresh state of the same data on the server.
Make sure you never cache sensitive data on the client side like credentials or Credit Card information.
Uniform Interface
This is possibly the most important of all the core REST constraints. The idea here is that once a developer uses your REST API implementation, he/she should be able to apply the same techniques and principles to work with another RESTful API implementation as well.
There are 4 sub-constraints within this main constraint.
1. Identification of Resources
We have already seen what resources are in the previous section but to recap, a resource is an abstract target of interest for API clients that maps to a certain set of information.
This sub-constraint requires that each resource must be identified by a unique and stable identifier. Unique meaning the same identifier should not point to two or more resources and stable meaning that it should not change with time. If it does change then the API should handle this gracefully and let the clients know what the new identifier is for accessing the same resource.
For REST Web APIs, URIs serve as this unique and stable identifier for resources. URI stands for Uniform Resource Identifier.
URIs are similar to URLs but technically URLs are considered a subset of URIs. Here is an excerpt from a good article on this topic:
The difference between a URI and a URL is that a URI can be just a name by itself, or a name with a protocol that tells you how to reach it—which is a URL.
We'll be using URIs and URLs interchangeably for the rest of this discussion.
The below URI identifies the resource "list of todos" or simply "todos".
GET https://jsonplaceholder.typicode.com/todos
Here, the URI identifies the resource "a todo with ID 1".
GET https://jsonplaceholder.typicode.com/todos/1
Lastly, this URI identifies the resource "a random image with width 200px and height 300px".
GET https://picsum.photos/200/300
2. Manipulation of resources through representations
This sub-constraint states that when a client obtains a representation of a resource from the API server, it should have all the information that the client needs to modify or delete that resource.
Consider this GET request
GET https://jsonplaceholder.typicode.com/todos/1
This returns a response as
{
"userId": 1,
"id": 1,
"title": "delectus aut autem",
"completed": false
}
This response is a representation in the form of JSON.
Just as clients receive this representation in the response of the API service, they can also send a representation in an API request to alter the state of the resource on the API server. The representation sent by the client becomes the new state of the resource.
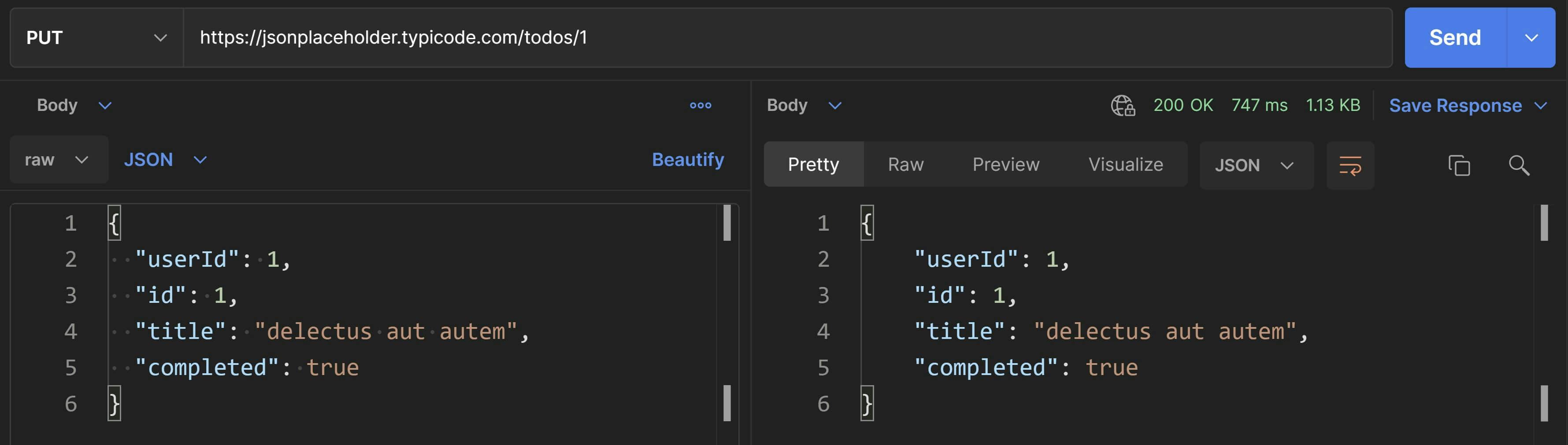
For example, say suppose I'd like to mark the above todo as completed, then I'll send the new state of the todo resource in a JSON representation to the same API service but this time using the PUT HTTP verb like this:
PUT https://jsonplaceholder.typicode.com/todos/1
{
"userId": 1,
"id": 1,
"title": "delectus aut autem",
"completed": true
}
The PUT HTTP verb is used for UPDATE operations while POST is used for CREATE operations.
Since we cannot directly send a PUT request like we can send a GET request by visiting the URL in the browser, we're going to use Postman for sending this PUT request along with the representation payload. You can either install the browser extension or the desktop app whichever you prefer.
Next, enter the details as shown in the screenshot and hit SEND. The response will appear on the panel on the right side.
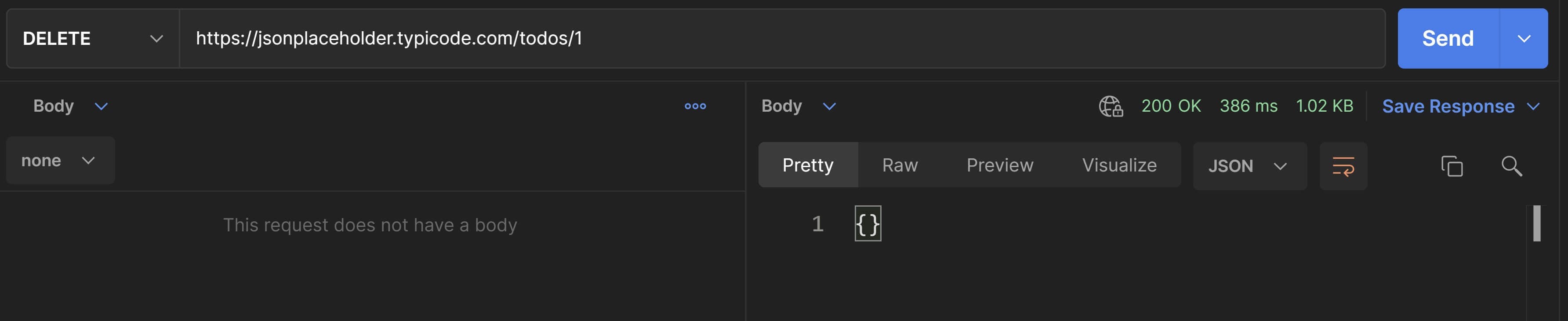
Deleting a resource doesn't require the client to specify a new state for the resource because the resource will get deleted anyways. So the only requirement is the URI that specifies the resource to be deleted. Let's delete the todo resource from the above example.
DELETE https://jsonplaceholder.typicode.com/todos/1
Again, we'll use Postman. Enter the details as in the below screenshot and hit SEND. Don't worry if you didn't get back any representation this time because it is standard for DELETE operations in REST not to return any representation because the resource has been removed.
3. Self-descriptive messages
This sub-constraint states that messages exchanged between the client and the server should carry all the information that the receiving party needs to process that message successfully.
Messages include not just the representations of the data as described above but also metadata that describe the data payload being sent.
In RESTful Web APIs, this metadata usually refers to HTTP headers.
For example, consider this GET request.
GET https://jsonplaceholder.typicode.com/todos/1
If you visit this link in the browser and inspect the request headers in Dev Tools, you'll see something like this:
GET /todos/1 HTTP/2
Host: jsonplaceholder.typicode.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:98.0) Gecko/20100101 Firefox/98.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8
...
...
Cache-Control: no-cache
...
...
This tells the server that this is a GET request, sent via HTTP to the host jsonplaceholder.typicode.com and the resource that was requested i.e. /todos/1.
It also provides information like the Accept header that indicates what mime-types the client is capable of comprehending, the Cache-Control header that controls caching preferences and User-Agent that provides information about the client application that sent the request. These are just some of the HTTP header fields included in the request.
The response from the API server contains the data payload and headers that help clients understand how to process the response.
HTTP/2 200 OK
date: Tue, 15 Mar 2022 15:26:02 GMT
content-type: application/json; charset=utf-8
...
...
cache-control: max-age=43200
...
...
etag: W/"53-hfEnumeNh6YirfjyjaujcOPPT+s"
...
...
age: 19587
...
...
This response tells the clients that it was sent via HTTP, the date when the response was sent, the Content-Type that indicates this is a JSON response, Cache-Control, Age and ETag headers that specify caching instructions from the server.
4. Hypermedia As The Engine Of Application State(HATEOAS)
This sub-constraint states that a representation of a resource returned from the API server to the client should contain hypermedia references usually in the form of reference links to perform further actions or to access more information on the same resource or related resources.
This enables the client application to sort of browse the API in the same way you'd browse an HTML web page that has links to other websites.
This also enables the API to return compact representations that provide the most relevant information up-front with the option to access more details using these hypermedia references.
Moreover, this makes using the API much easier for client developers because once they receive the response for the root resource, they can use these hypermedia references to access other resources without referring to the API documentation.
There is also no need to hardcode API URLs in the client codebase as those URLs will be provided in the API response. This allows the API server to change URIs(only if absolutely necessary) without causing any breaking changes on the client-side.
We'll again consider the example of the Github API.
Go ahead and visit the link given below in your browser.
https://api.github.com/users/saurabh-misra
The response will look something like this:
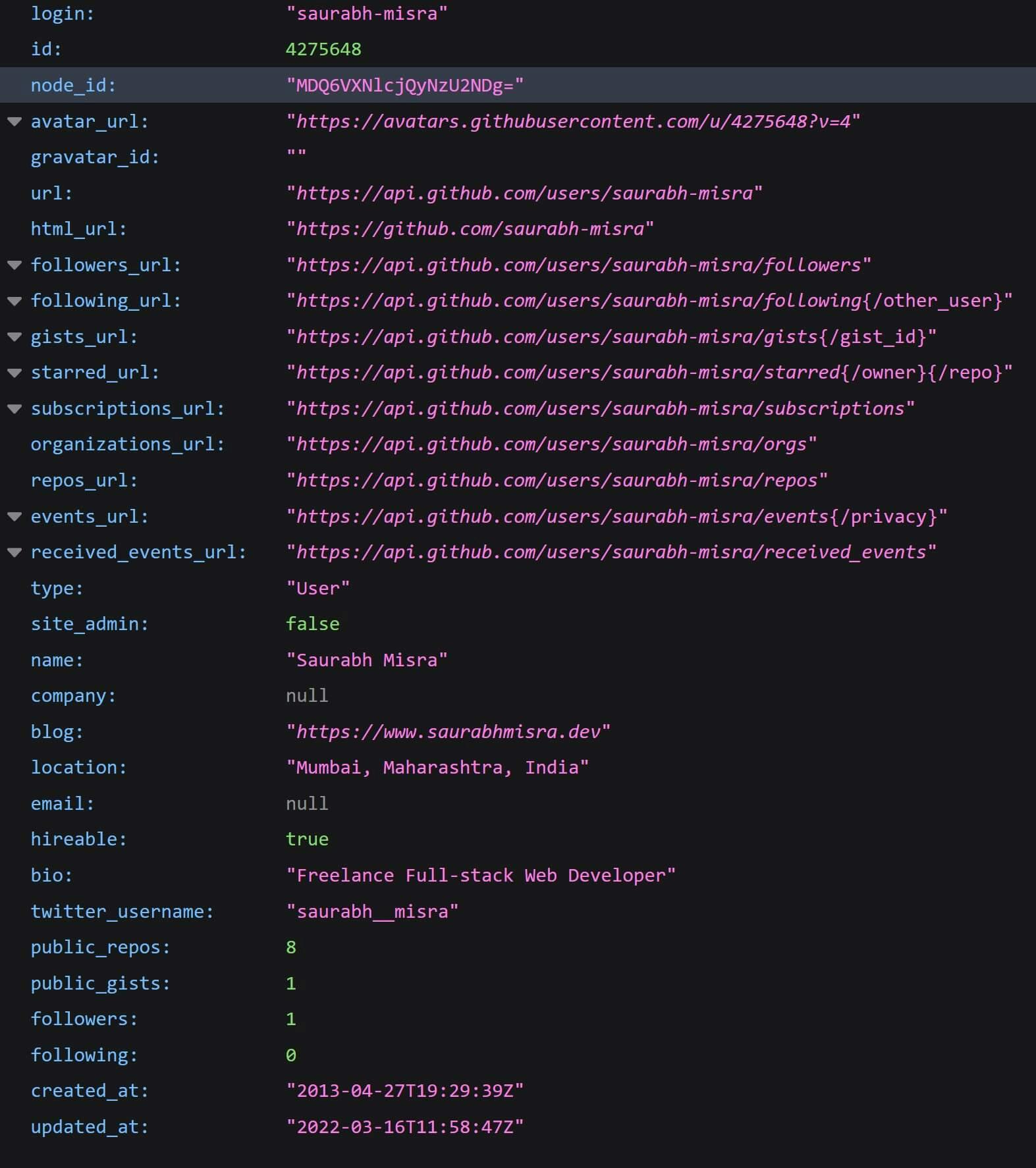
As you can see that the response contains lots of information relevant to my Github profile. But it also provides so many URLs that point to other Github API services.
If you visit the link in the repos_url property, you'll get a list of repositories with relevant information about each repository along with URLs that'll fetch even more information about that particular repository.
Doesn't this feel similar to browsing webpages in your browser? Only difference is that while you browse webpages rendered in HTML using links on the webpage, API clients explore and browse API endpoints using links in the API response.
In the future, if Github decides to change the repos_url from /users/{username}/repos to /users/{username}/repositories, it won't cause breaking changes in the client applications as long as they use the repos_url property to browse the API and not hardcode the actual URL.
Layered System
This REST constraint allows the implementation of a layered architecture wherein the API implementation can reside on one server but source its data from a separate database server and maybe perform authentication from yet another server. There can even be intermediaries between the client and the server like proxies and gateways that can help with load-balancing and security.
From the client's perspective, it connected directy with the end server and has no knowledge of the intermediaries along the way. Also each layer is only aware of the existence of the next layer and not of layers beyond that.
Support for a layered architecture boosts scalability as concerns such as security, storage, authentication, request handling, etc are separated between different servers without burdening the client with any added complexity. But the disadvantages are that it adds latency because each request needs to go through several different layers. This latency can be reduced by utilizing effective caching strategies.
Code-On-Demand(optional)
In all of the constraints we have seen so far, API servers have always been concerned with sending data in response to a client request and had nothing to do with how it was presented on the client side.
The last of the REST constraints, Code-On-Demand states that if needed, the server can send executable code like applets or client-side scripts in JavaScript that can extend the functionality of a client.
For example, clients may call an API to receive directly executable code that renders UI widgets such as newsletter subscription pop-ups or customer support chat windows.
This is an optional constraint as this is an additional feature rather than a mandatory constraint. In most cases, API implementations won't need to return executable code but if they do, they shouldn't feel like they are violating REST guidelines.
Conclusion
I hope this article helped you a gain a good understanding of what the REST architectural constraints are and how they empower the REST architectural style.
In the next article in this series, we'll learn how to practically implement each of these constraints while following a step-by-step tutorial for building our very own REST API. See you there 👉.
References and Further Reading
Namaste🙏! I'm Saurabh Misra, a Full-Stack Software Developer.
I have been building software since 2009. This blog serves as a means for me to share my knowledge and expertise with the software development community.
Connect with me on Twitter, LinkedIn and Github.
Visit my Blog for more articles.